Best practices for Sort, Filter, Page using MSSQL and ASP.NET MVC
This post more than any other, is for me to remember how I like to name things, and how to setup a high performance web application with large amounts of data needing queried in MSSQL. The example shows ASP.NET MVC whereas today I’d probably use Razor Pages on ASP.NET Core 2.0.
Summary
- Name things consistently
- Make SQL do the heavy lifting of: Sorting, Filtering, Paging.
- Keep data access as simple
- Source on Github
Background
I’ve been writing business apps for 16 years, with the last 10 being on MSSQL with ASP.NET. What I’ve noticed is that my applications are much simpler and more performant if I leave data manipulation to the database
Example App
- ASP.NET MVC app
- Service layer (DAL) - Repository pattern
- MSSQL
Conventions
Singular Table Names
CREATE TABLE [dbo].[Author] (
[AuthorID] INT IDENTITY (1, 1) NOT NULL,
[FirstName] NVARCHAR (255) NOT NULL,
[LastName] NVARCHAR (255) NOT NULL,
[DateOfBirth] DATE NULL,
PRIMARY KEY CLUSTERED ([AuthorID] ASC)
);- Identity Ints for the PK (not GUIDS)
- AuthorID for ID Column (not ID)
- Singular table names preferred see here and here so that Master detail link tables are well named eg AuthorAddress.
Plural Repository Names
public class AuthorsRepository
{
public List<Author> GetAuthors()
{
using (var db = Util.GetOpenConnection())
{
return db.Query<Author>("SELECT * FROM Author ORDER BY LastName").ToList();
}
}
}Dapper maps what is returned from SQL to a List of Authors.
Singular Model Names
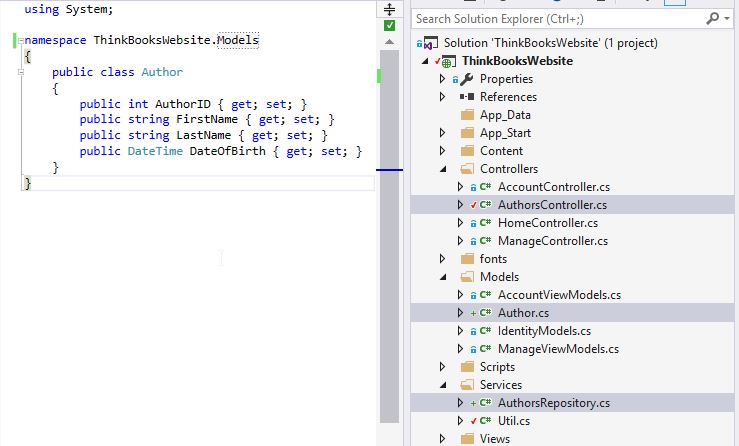
Keep models simple. Here is current solution of Controllers/Models/Services (Repository and Utility static class)
Plural Controllers
RESTful resources are mostly plural eg Spotify API so I will use:
/Authors/
/Authors/Details/1
/Authors/Edit/1
/Authors/Delete/1
/Authors/CreateUse Full Blown SQL
If performance is an issue from the start use full SQL on your Dev machine (or whatever version you’ll run in Prod) and a way of loading real data fast using Fastmember is a very good start compared to Datatables.. Full SQL means you will be able to use Database Engine Tuning Advisor to help with indexes.
MiniProfiler has helped me a lot to quantify performance.
No Linq
For the next sections see a Repository of Authors
For this project I found using SQL and Dapper to be perfect. I didn’t need linq. Linq may have been much more handy with a smaller dataset, and where performance wasn’t critical.
I found that for large datasets using dynamic sql with parameterised variables to be incredibly performant and flexible. In the code above you’ll notice an inline variable sanitizedSortColumn.
Ordering
CASE strategy works but it doesn’t use indexes.
The solution is to use plain old SQL (with all the usual caveats about SQL injection!)
I found that if you are constrained in a large organisation, then sp_executesql works well if you ‘have to use SP’s’!
Paging
SQL2005 - CTE’s works
SQL2012 and greater - ORDER BY OFFSET FETCH seems to perform better
var sql = @"
SELECT a.*, s.Name AS AuthorStatusName FROM Author a
INNER JOIN AuthorStatus s ON a.AuthorStatusID = s.AuthorStatusID
WHERE (@AuthorID IS NULL OR AuthorID = @AuthorID)
AND (@FirstName IS NULL OR FirstName LIKE CONCAT(@FirstName,'%'))
AND (@LastName IS NULL OR LastName LIKE CONCAT(@LastName,'%'))
AND (@DateOfBirth IS NULL OR DateOfBirth = @DateOfBirth)
ORDER BY " + sanitizedSortColumn + " " + sortDirection + @"
OFFSET " + offset + @" ROWS
FETCH NEXT " + numberOfResults + " ROWS ONLY";
Counting
Counts are expensive. Some background information
I’ve used the following technique on large tables which gives blazing fast performance
-- If we are are just want to know how many rows are in the entire tables really quickly
if (authorIDFilter == null && dateOfBirthFilter == null && firstNameFilter.IsNullOrWhiteSpace() && lastNameFilter.IsNullOrWhiteSpace())
{
sqlCount = @"SELECT SUM(p.rows)
FROM sys.partitions AS p
INNER JOIN sys.tables AS t
ON p.[object_id] = t.[object_id]
INNER JOIN sys.schemas AS s
ON t.[schema_id] = s.[schema_id]
WHERE p.index_id IN (0,1) -- heap or clustered index
AND t.name = N'Author'
AND s.name = N'dbo'";
}
else
{
sqlCount = @"SELECT COUNT(*) FROM Author
WHERE(@AuthorID IS NULL OR AuthorID = @AuthorID)
AND(@firstName IS NULL OR FirstName LIKE CONCAT(@firstName, '%'))
AND(@LastName IS NULL OR LastName LIKE CONCAT(@LastName,'%'))
AND(@DateOfBirth IS NULL OR DateOfBirth = @DateOfBirth)";
}
If you are counting over multiple tables and are having daily jobs running running. Do the processing and put total main query count into a helper table.
How to handle the Front End
Keeping filters sticky, Paging, Keeping the URL clean and more are more easily explained by looking at this example.